
Product
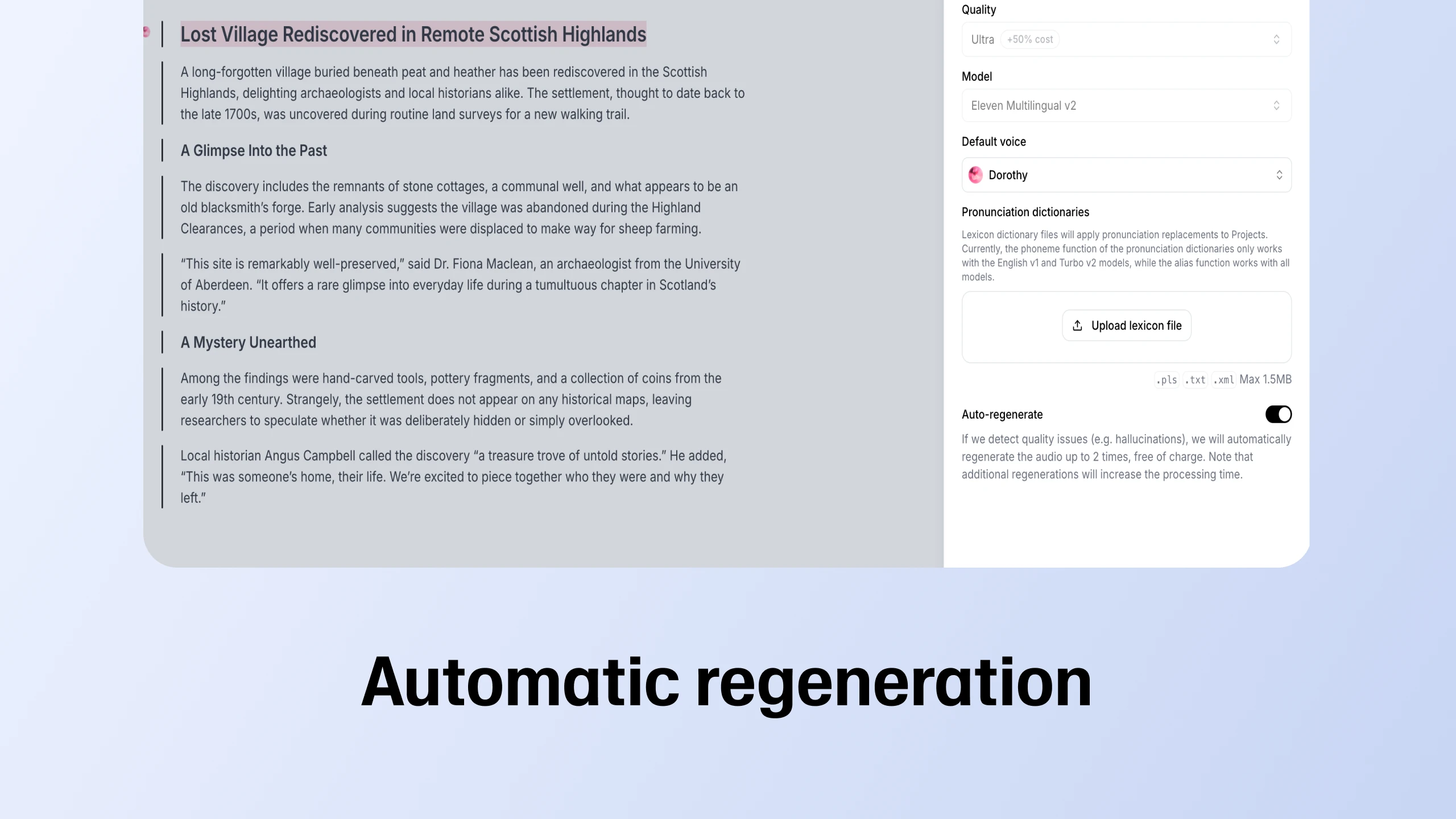
Auto-regenerate is live in Projects
Our long form text editor now lets you regenerate faulty fragments, adjust playback speed, and provide quality feedback
Voice conversion lets you transform one person's voice into another’s. It uses a process called voice cloning to encode the target voice - ie, the voice we convert to - and generate the same message spoken in a way which matches the target speaker’s identity but preserves the original intonation.
High quality voice conversion and voice cloning technology have the potential to revolutionise the way content is produced, delivered and interacted with across a range of industries. They promise to optimise production time and costs and to provide those who share their voices to train conversion algorithms with ways to earn passive fees.
Although we develop voice conversion software at Eleven as part of our tool package, our research into voice cloning and voice synthesis primarily fuels the development of our chief product which we plan to release early next year: the identity-preserving automatic dubbing tool.
Our goal here is to make all spoken content accessible across languages in the original speaker’s voice, at a click of a button. Imagine an educational YouTube video in English. If somebody only speaks Spanish (but would otherwise find the subject interesting if only they knew the language), that’s a problem. Sure, captions provide a solution but our aim is to give a much more immersive and entertaining way of engaging with content. We want to be able to generate that same person speaking the same message naturally in native-grade Spanish, even if they really don't.
To this end, voice cloning allows us to preserve their identity - the sound of their voice. We use it to generate new utterances in a different language so that they sounds as if it's the same person speaking.
Voice conversion comes into play because we want to preserve their emotions, intent and style of delivery for maximum immersion. We train robust multi-language models, that enable us to parse utterances in the source language and map them onto the target language with the right intonation.
To convert one person’s voice into another’s i.e., source speech into target speech, we need an algorithm to express source speech content with target speech characteristics. A good analogy here is face-swapping apps which let you mix your face with somebody else’s to create a picture of both as one.
The way to go about this is to take the image of a face and map its attributes. The dots in the example below do just that: they’re the limits inside which the other face’s features would be rendered.
In voice conversion, we need a way for the algorithm to encode target speech properties. The algorithm is trained on a set of data comprising many examples of that speech. It breaks those samples down to a fundamental level - the "atoms" of speech, so to say. Speech comprises sentences. Sentences are comprised of words. Words are made up of phonemes and they mark the characteristics of target speech. They're the fundamental level at which the algorithm operates.
The trick in voice conversion is to render source speech content using target speech phonemes. But there’s a tradeoff here, much as there is in the face-swapping example: the more markers you use to map one face's attributes, the more constraints you impose on the face you map inside them. Fewer markers means less constraints. The same is true of voice conversion. The more preference we give to target speech, the more we risk becoming out of sync with source speech. But if we don't give it enough preference, we risk losing much of what makes that speech characteristic. For instance, if we were to render the recording of somebody shouting angrily in Morgan Freeman's voice, we'd be in trouble. Give too much preference to source speech emotions and the price we pay is losing the impression it's really Morgan Freeman speaking. Too much emphasis on his speech pattern and we lose the emotional charge of source speech.
Ethical concerns over voice cloning deserve addressing as the potential to misuse the technology has increasing numbers of people worried. In 2020 audio deepfakes were used by scammers impersonating a CEO over a phone call to authorise a bank transfer of $35 million. A technology which can convincingly make it seem as if somebody said something they didn’t naturally raises fears of being used to disinform, defame or commit fraud. Similarly, voice conversion raises important questions about copyright infringement if it allows users to capitalize on content generated without consent from voice owners.
At Eleven we feel the need to do what we can to make sure our technology isn't used for nefarious purposes and to implement safeguards to protect from its dangers:
We believe that fear of abuse should not be the dominating factor guiding our attitude towards powerful new technologies. Rather we should strive to ensure appropriate safeguards are introduced at the time of development to minimise the risk of harm while we make the most of the potential the technology offers to the wider community.
Voice conversion and voice cloning technology promise to revolutionise filmmaking, television, content creation, game development, podcast and audiobook, as well as advertising industries. But their applications go beyond the commercial with potential uses in medicine, education and communication.
Voice cloning is paving the way for a future where any content can be generated in any langauge and voice to reach millions of people worldwide and to create an entirely new economy. Our goal at Eleven is to help bring this future about.
Our long form text editor now lets you regenerate faulty fragments, adjust playback speed, and provide quality feedback

Developers brought ideas to life using AI, from real time voice commands to custom storytelling