Research

The first AI that can laugh
Our model produces emotions like no other

For some, Real-time Dubbing evokes an image of the Babelfish from Hitchhiker's Guide to the Galaxy.
The Babelfish “feeds on brainwave energy, absorbing unconscious frequencies and excreting a matrix of conscious frequencies to the speech centers of the brain.” In practice, this means that when you put one in your ear, any time anyone speaks to you in any language, you will hear them instantly as if they are speaking in your native language (and you don’t hear the source audio at all).
Until we can read brainwaves, we need to listen to the speaker’s words and translate them to our target language. Attempting to translate each word, as they leave the speaker’s mouth, poses real challenges.
Imagine a scenario where you want to translate from English to Spanish. The speaker starts with “The”. In Spanish, “The” is translated to “El” for masculine words and “La” for feminine words. So we can’t translate “The” with certainty until we hear more.
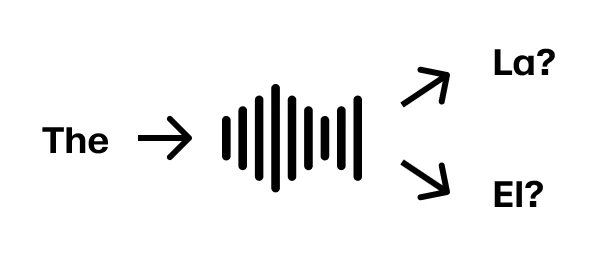
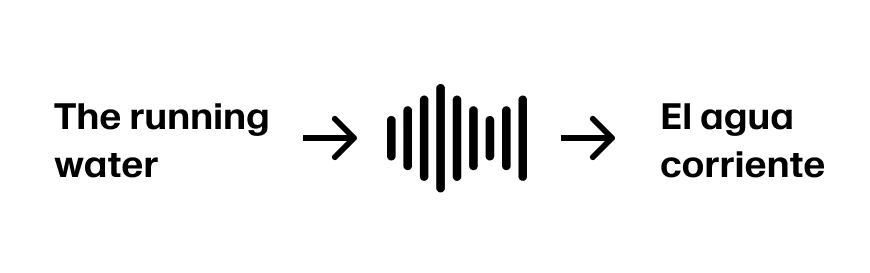
Imagine the speaker continues “The running water”. Now we have enough information to translate the first three words to “El agua corriente”. Assuming the sentence continues “The running water is too cold for swimming” we’re in great shape.
But if the speaker continues “The running water buffalo…” we need to backtrack.
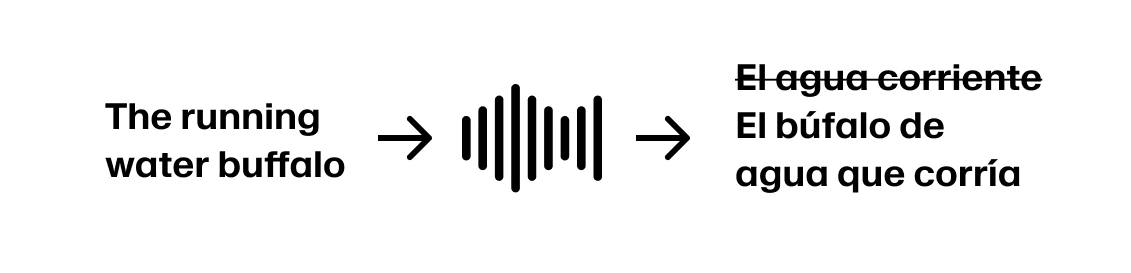
To belabor the point, if the speaker continues “The running water buffalo protected her calf”, we should have started the sentence with “La búfala” instead of “El búfalo”.
These “garden path” sentences, ones that start in a way where the listener’s initial interpretation is likely incorrect, are present in many languages.
For some use cases, you may be willing to accept that you will have to back track after starting to dub too quickly. For others, you can choose to add latency for more accuracy. Given that some latency is inherent to all dubbing use cases, we define “real-time” dubbing as a service through which you can continuously stream audio and get translated content back.
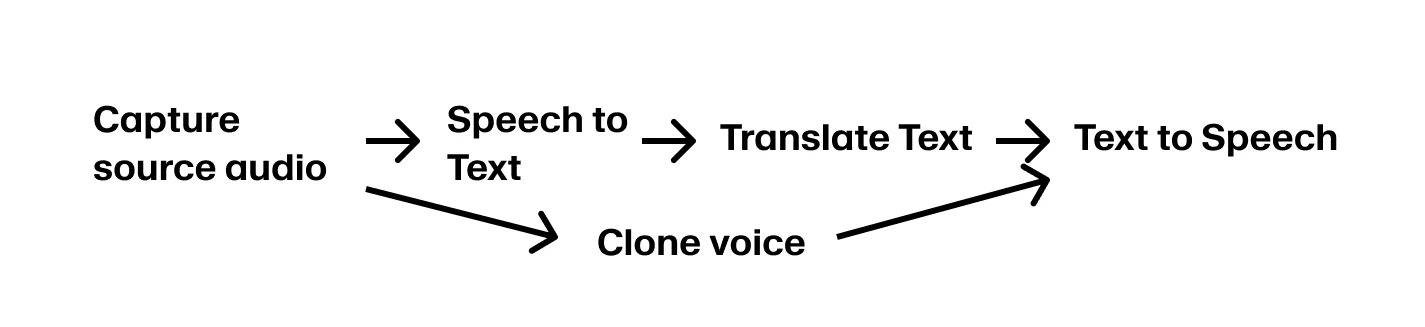
The best commercial applications of real-time dubbing are those where
Forbes reported in 2019 that the NBA is earning $500m in international tv rights. The NFL is now hosting games in Brazil, England, Germany and Mexico as it sees international expansion as a core revenue driver in the future.
And while most sporting events are meant to be consumed live, people are already accustomed to some latency whether they know it or not. The time it takes footage captured in the stadium to hit your screen at home can range anywhere from 5 seconds to a couple of minutes.
Typically there are multiple camera and sound operators on site who stream their footage to a production facility. The production facility switches between camera feeds, mixes the audio, overlays graphics, and adds commentary. They may also intentionally add an additional delay to listen for and bleep out curse words or other unexpected content.
The main production feed is sent to the broadcast network who add their own branding and commercials and distribute the content to their local networks. Finally, the last mile providers share the content with consumers via cables, satellite feeds, and streaming services.

Many producers report it would be acceptable to add up to 20 seconds of additional latency for dubbing. The additional latency is more than compensated for by the fact that viewers can listen in their native language.
Sports companies care most about providing a quality product and they believe the key to a quality product is effectively capturing the emotion and timing of the broadcasters. “He shoots, he scores!” needs to be delivered with enthusiasm.
Our voice cloning models that underpin our dubbing service are able to capture the original speaker’s emotion and delivery. Unlike with translation, more context does not always lead to a better result. However, we aren’t yet at the emotional level of a Spanish football commentator!
Each voice clone is an average of its inputs. If you combine a line that’s delivered flat like “They are going to need to be more aggressive with only two minutes remaining.” with “He shoots, he scores!”, the resulting clone will be the average delivery of the two.
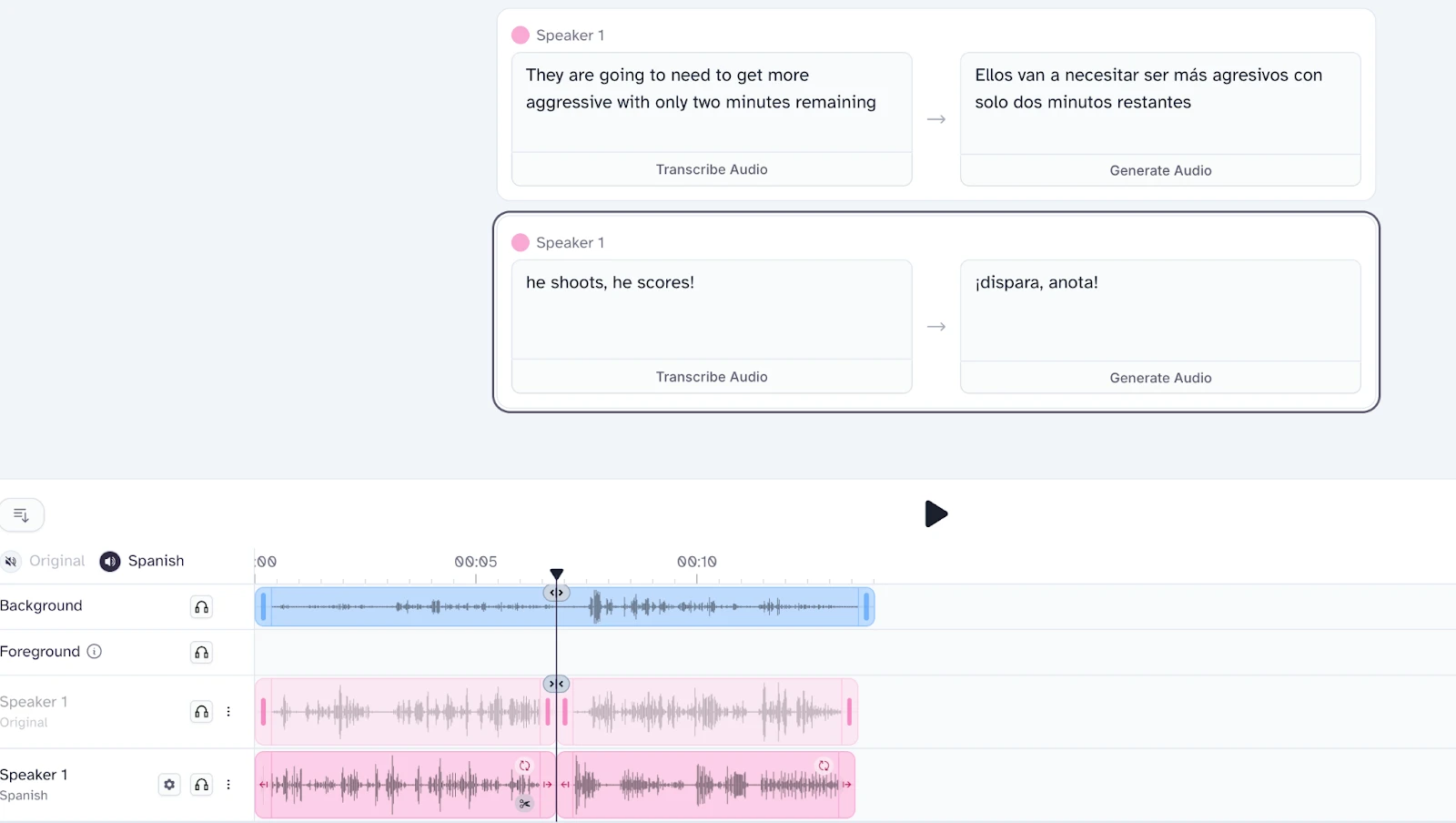
Today, we can overcome this by having shorter context lengths for voice cloning than for transcript translation. In the future, we expect to find additional gains by providing additional context (like image and video) to our dubbing model or creating an “emotional transcript” of the original speaker and using that to direct the delivery of the dubbed audio.
Like “live” Sports, News Broadcasting goes through a production pipeline that adds delays. From our conversations with media companies, nailing the emotion (while important) is less critical and often easier because most newscasters have a very consistent delivery. It is paramount though that the translation is both accurate and nuanced.
On top of the chance that there is a failure in the automated translation service, some concepts have no direct translation. Consider the following:
"The community gathered for a day of remembrance, where survivors shared their stories and elders performed traditional prayers for healing."
Spanish: "La comunidad se reunió para un día conmemorativo, donde los sobrevivientes compartieron sus historias y los ancianos realizaron oraciones tradicionales para la sanación."
While technically accurate, "survivors" vs "sobrevivientes" carries different weight in contexts of historical trauma - in English it often implies resilience and dignity, while "sobrevivientes" can emphasize victimhood. Similarly, "performed prayers" vs "realizaron oraciones" differs in reverence - "performed" acknowledges ceremonial significance while "realizaron" can sound more procedural.
To allow for natural, in-person conversation between people who don’t speak the same language, you need near instantaneous translation.
By using the next token prediction probabilities of LLMs, you have a real-time model of the likelihood of where a sentence is going.
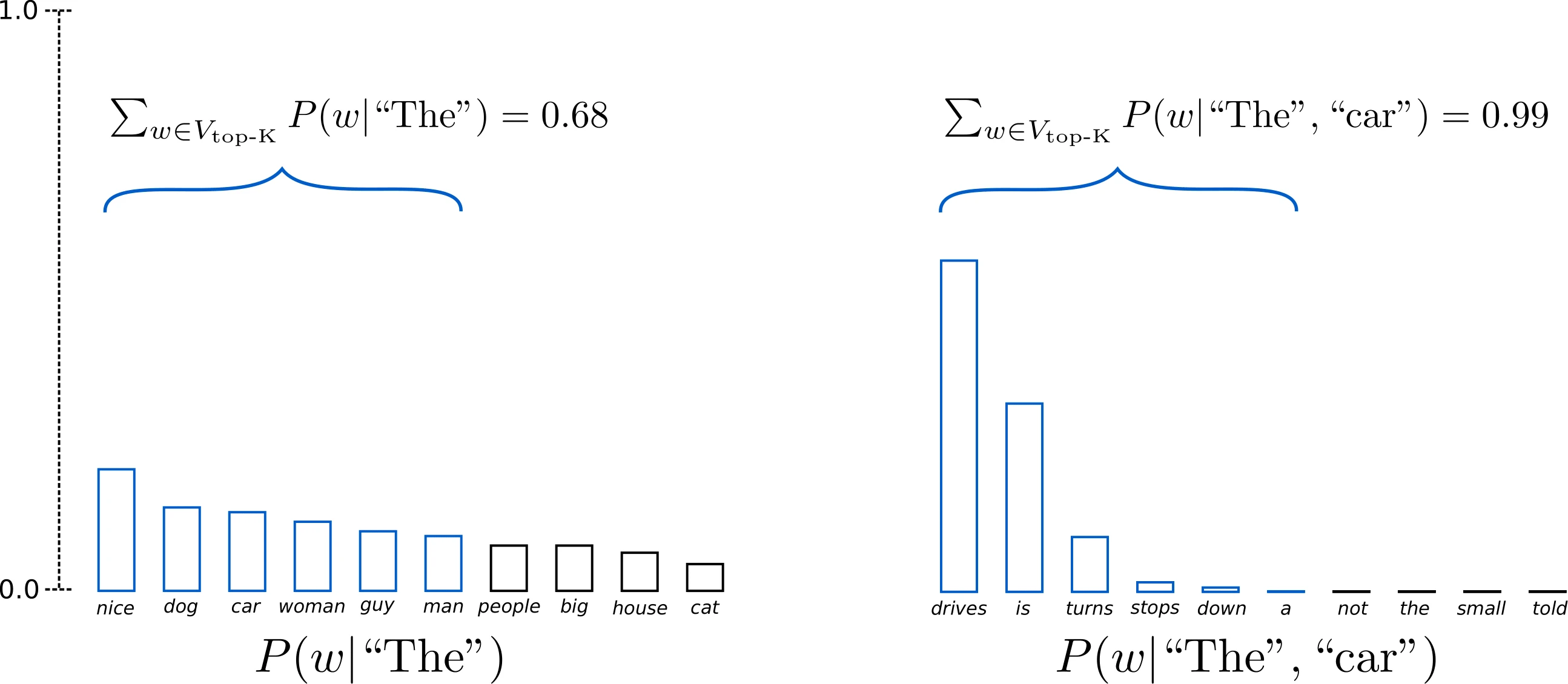
Image source - Hugging Face "How to generate text"
If we fine tune this next token prediction model on an individual speaker, we will have a reasonable understanding of where they are going next. Using this information, we can “cheat” by front running the translation and speech generation when we have a high certainty about where the speaker is going next.
Find this interesting and want to work with us on the future of AI Audio? Explore open roles here.
Our model produces emotions like no other
We’re deploying our own generative model which lets users design entirely new synthetic voices