
Automate video voiceovers, ad reads, podcasts, and more, in your own voice
Explore the new features and pricing for OpenAI's text to speech (TTS) audio models. Learn to craft AI-generated voices easily with our straightforward guide.

OpenAI has just launched two Text to Speech (TTS) API models: TTS and TTS HD. Moreover, GPT-4 Turbo now has a 128k context window, fresher knowledge and a broadest set of capabilities. Together with the DALL·E 3 API for advanced image generation, and novel APIs for coding, the new developments will enable more sophisticated and efficient workflows.

OpenAI's pricing structure for their TTS offerings is designed to accommodate a wide range of needs and budgets:
OpenAI's commitment to innovation is evident in these developments, which would not only enhance the existing TTS technology but also expand the scope of what's possible in human-AI interactions.
The ChatGPT voice generator is not merely a technological tool, it's a gateway to immersive, multi-sensory experiences that make digital interactions more intuitive and encompassing.
Let's delve into its expansive capabilities:
Gone are the days when interactions with ChatGPT were limited to typing. Now, striking up a conversation is as simple as:
Imagine casually asking, "Tell me about the Renaissance period?" and having a nuanced, articulate reply echoed back.
This dynamic offers more than just answers. It provides an experience of human-like discourse with an AI.
OpenAI's new voice technology heralds an era of auditory diversity. From the tranquil tones of a baritone to the vibrant pitches of a soprano, OpenAI Voice encapsulates a spectrum of voices.
Beyond mere replication, this technology crafts synthetic voices that bear an uncanny resemblance to genuine human speech, enhancing authenticity in interactions.
However, it's important to note that while the potential applications are vast, they come with ethical considerations. The precision of voice synthesis, though remarkable, could be misused for deceit or impersonation.
OpenAI acknowledges these challenges and has actively taken measures to mitigate misuse, primarily by focusing on specific, beneficial use cases, like voice chat.
In the realm of Text-to-Speech (TTS) technology, while OpenAI's advancements hold immense promise, ElevenLabs has already set a gold standard with its innovative Generative Speech Synthesis Platform.
By harmonizing advanced AI with emotive capabilities, ElevenLabs delivers a voice experience that's not only lifelike but also contextually rich and emotionally nuanced.
The brilliance of ElevenLabs lies in its focus on the subtleties:
Automate video voiceovers, ad reads, podcasts, and more, in your own voice
The platform's versatility doesn't end with its vast voice offerings. Users can delve deep, fine-tuning outputs for the perfect balance between clarity, stability, and expressiveness with a dedicated voice lab.
With intuitive settings, one can exaggerate voice styles for dramatic effects or prioritize consistent stability for formal content.
Understanding the ever-evolving needs of developers, ElevenLabs has designed an ultra-responsive API. With ultra-low latency, it can stream audio in under a second.
Furthermore, even non-tech users can harness the power of this platform, refining voice outputs with user-friendly adjustments for punctuation, context, and voice settings.
OpenAI's potential TTS might be on the horizon, but ElevenLabs has already realized many of the anticipated features.
Passionately engineered by a team devoted to revolutionizing AI audio, ElevenLabs prioritizes user experience, from genuine language authenticity to ethical AI practices.
ElevenLabs isn't just a platform—it's a testament to what's achievable in the TTS domain, showcasing features that might still be in the realm of speculation for others.
As OpenAI takes its steps into this field, the benchmarks set by ElevenLabs will undoubtedly serve as significant milestones.
When comparing ElevenLabs to OpenAI's forthcoming TTS model, several key distinctions emerge:
The future of TTS technology is collaborative. By making OpenAI's API compatible with ElevenLabs' technology, we envision a seamless integration where users can benefit from the strengths of both platforms. This compatibility would allow users to utilize OpenAI's TTS for tasks like speech-to-text conversion while taking advantage of ElevenLabs' voice cloning and low-latency playback for an enriched auditory experience.
Ready to take your audio content to the next level? Dive into the realm of lifelike, context-aware audio generation perfected for your needs. Experience ElevenLabs Text to Speech today and be part of the TTS revolution.

Easily integrate our low-latency Text to Speech API and bring crisp, high-quality voices to your applications with minimal coding effort
Tune in as ElevenReader AI co-hosts generate smart podcasts from your PDFs, articles, ebooks and more
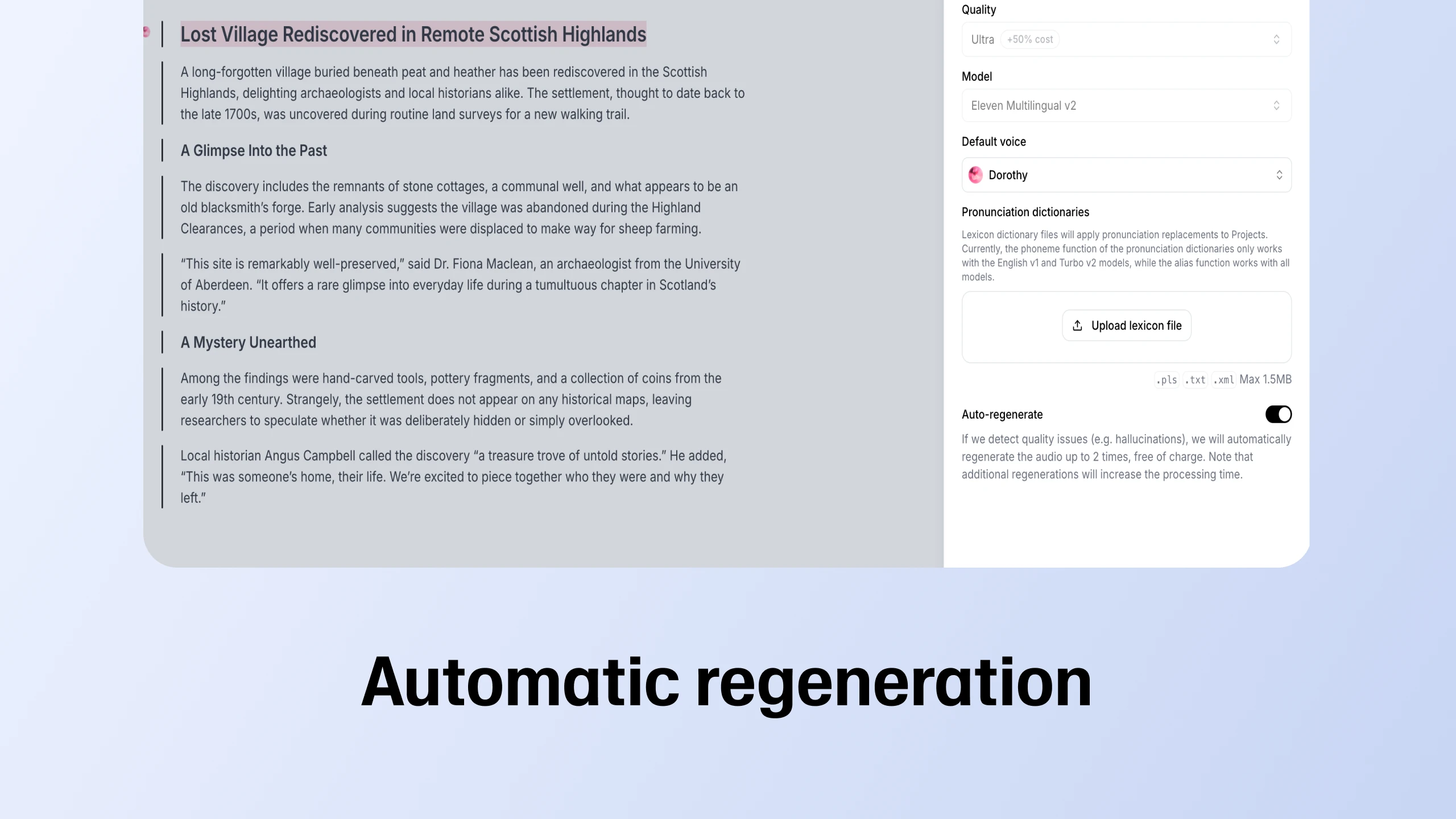
Our long form text editor now lets you regenerate faulty fragments, adjust playback speed, and provide quality feedback