Product
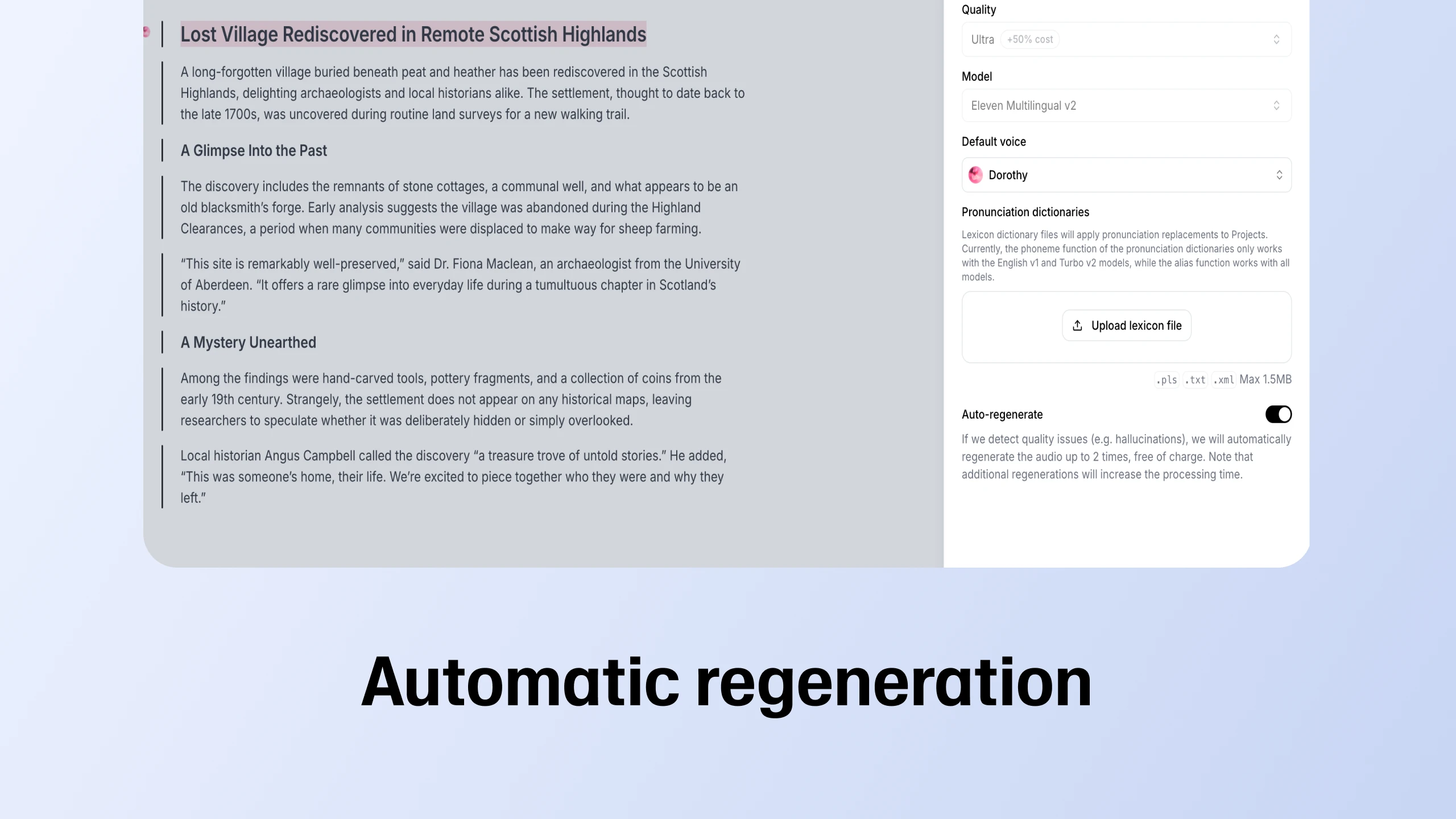
Auto-regenerate is live in Projects
Our long form text editor now lets you regenerate faulty fragments, adjust playback speed, and provide quality feedback
Our current deep learning approach leverages more data, more computational power, and novel techniques to deliver our most advanced speech synthesis model

Today, we’re thrilled to launch Eleven Multilingual v1 - our advanced speech synthesis model supporting seven new languages: French, German, Hindi, Italian, Polish, Portuguese, and Spanish. Building on top of the research that powered Eleven Monolingual v1, our current deep learning approach leverages more data, more computational power, and novel techniques inside an increasingly sophisticated model, capable of understanding textual nuances and delivering an emotionally rich performance. This advancement expands the creative horizons for creators, game developers, and publishers, and it paves the way for using generative media to create more localized, accessible, and imaginative content.
The new model is available across all subscription plans and you can try it out now on our Beta platform.
To use it, simply select it from the newly-added drop-down menu within the Speech Synthesis panel.
Similarly to its predecessor, the new model is based entirely on our in-house research. It retains all the strengths that made Eleven Monolingual v1 an excellent storytelling tool, such as the ability to adjust delivery based on context and to convey intent and emotions hyper-realistically. These features have now been expanded to newly supported languages through multilingual data training.
A noteworthy feature of the model is its capacity to identify multilingual text and articulate it appropriately. You can now generate speech in multiple languages using a single prompt while maintaining each speaker's unique voice characteristics. For the best results, we recommend providing a single language prompt. Although the model can already perform reasonably well with multiple languages at once, further enhancements are needed.
The new model is compatible with other VoiceLab features i.e. Instant Voice Cloning and Voice Design. All created voices are expected to maintain most of their original speech characteristics across all languages, including their original accent.
This being said, the model has known limitations: numbers, acronyms, and foreign words sometimes default to English when prompted in a different language. For instance, the number "11", or the word “radio”, typed in a Spanish prompt may be pronounced as they would be in English. We recommend spelling out acronyms and numbers in the target language as we work on improvements.
ElevenLabs was started with the dream of making all content universally accessible in any language and in any voice. Our team members come from all across Europe, Asia and the US. As our team and the world become increasingly multilingual, we’re ever more united behind the vision of making human-quality AI voices available in every language.
The latest iteration of our Text-to-Speech (TTS) model is just the initial stepping stone on our path to making this vision a reality. With the advent of human-quality AI voices, users and businesses can now craft and customize audio content according to their needs, priorities and preferences. This has already shown the potential to level the playing field for creators, small businesses, and independent artists. By harnessing the power of AI audio, users can now develop high-quality auditory experiences that rival those produced by larger organizations with more resources.
Those benefits now extend to multilingual, multicultural and educational applications by empowering users, companies, and institutions to produce authentic audio that resonates with a broader audience. By providing an extensive range of voices, accents, and languages, AI helps bridge cultural gaps and promotes global understanding. At Eleven, we believe this newfound accessibility ultimately fosters greater creativity, innovation, and diversity.
Content creators who seek to engage with diverse audiences now have the tools to bridge cultural gaps and foster inclusivity.
Game developers and publishers can create immersive, localized experiences for international audiences, transcending language barriers and connecting with players and listeners to maximize engagement and efficiency, at no loss to quality or accuracy.
Educational institutions now have the means to produce audio content for various users in their target languages, bolstering language comprehension and even pronunciation skills, as well as catering to different teaching styles and learning needs.
Accessibility institutes can now further empower people with visual impairments or learning difficulties by providing them with means to easily convert less accessible resources to a medium that suits their needs, both in content and form.
We can’t wait to see our current and future creators and developers push the limits of what’s possible!
Our long form text editor now lets you regenerate faulty fragments, adjust playback speed, and provide quality feedback

Developers brought ideas to life using AI, from real time voice commands to custom storytelling