
Product
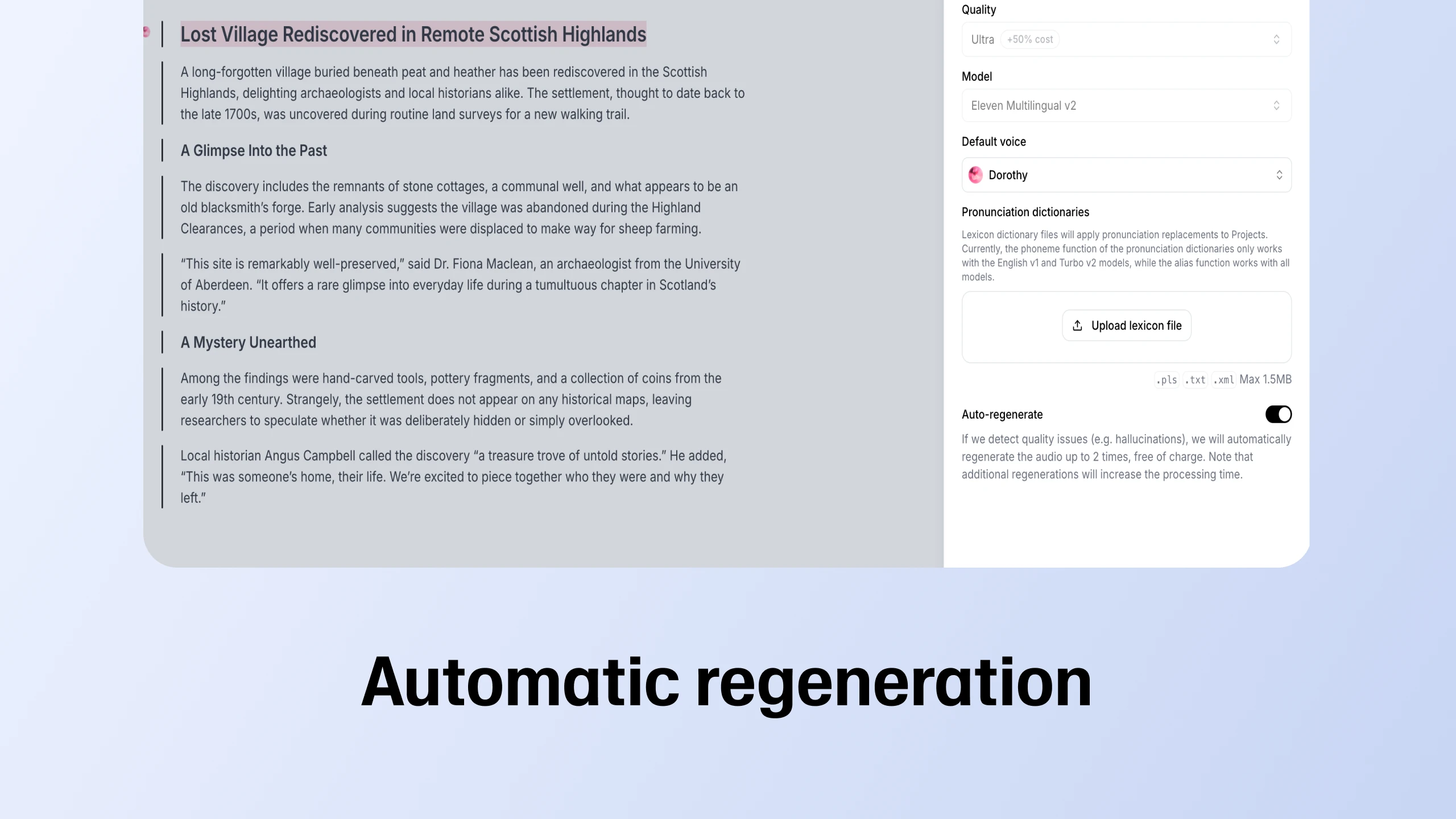
Auto-regenerate is live in Projects
Our long form text editor now lets you regenerate faulty fragments, adjust playback speed, and provide quality feedback
We're a voice technology research company. We use artificial intelligence (AI) and machine learning (ML) to bring the most powerful speech synthesis, voice conversion and dubbing tools to content creators, web platforms and production studios across industries.
Dubbing is a process for providing a film with a different language soundtrack. What people commonly mean, though, is replacing the original actors' voices with those of performers speaking a different language - aka "re-voicing" - traditionally a costly and time-consuming task. At Eleven, we use AI to do this automatically while preserving the actors' original voices across languages.
Voice conversion allows one person to speak in the voice of another. Also known as voice cloning, it's a process for encoding a target voice and overlaying it onto a source voice. Speaking in somebody else's voice raises ethical concerns since it can be used for nefarious purposes, but at Eleven we're committed to only employ our technology with the individual's consent or for demonstration purposes in a way that doesn't give rise to conflicts of interests.
Text-to-speech (TTS) is the root of all speech synthesis technology. TTS tech improved radically over the years though it still often sounds robotic. That's because pronouncing words fluently is on its own insufficient to give speech human quality. It's the intent-driven tone and pacing that come from understanding what is being said that make it sound natural. Again, at Eleven, we try to achieve just that: by exposing our model to a wealth of human-speech data, we train it to understand both the logical and emotional context of utterances, and to adjust delivery accordingly. We can also override default delivery to any desired effect.
Our dubbing tool lets you automatically re-voice a video in a different language while preserving the distinctive features of the original speaker's voice. We're the first company on a mission to provide dedicated tools for speech-to-speech translation that preserve speaker identity between languages. Our technology allows you to produce multilingual, localized audio tracks spoken with native-grade fluency and vocabulary, in your own voice, with your speech pattern preserved, and without the need to re-edit the visuals. At Eleven we imagine a future where all spoken content is accessible in any language across streaming, film, podcasts, audiobooks, gaming, advertising, as well as, eventually, real-time conversation. We hope to help bring this future about by providing a vastly more immersive and seamless experience than captioning ever could. The first iteration of our tool provides English to European Spanish dubbing.
Attaining production quality in automatic dubbing is only possible if we make strides in two adjacent voice tech areas - voice conversion and speech generation for which we also develop dedicated tools, in parallel with our dubbing software. Our products here support both voice cloning and synthetic speech. We go beyond delivering human-sounding, non-robotic voices (or even speech that’s indistinguishable from the original when trained on a sample set). We can precisely adjust the tone of utterances to any desired effect as well as generate countless iterations within a particular style of delivery - just like an actor would.
In short, our dubbing tool seeks to allow existing content to reach a wider audience. Our speech generation and voice conversion tools seek to optimise time and cost involved in producing new content while maximising production value. Through dubbing we primarily hope to both enable creators to widen their reach and to help prospective audiences discover content they find relevant and captivating, regardless of what language they understand.
Our long form text editor now lets you regenerate faulty fragments, adjust playback speed, and provide quality feedback

Developers brought ideas to life using AI, from real time voice commands to custom storytelling