

Automate video voiceovers, ad reads, podcasts, and more, in your own voice
We’re launching the AI voice translation tool next month. This allows users to convert any audio or video content into a different language while maintaining the original speaker's voice. Our goal is straightforward: make multilingual content accessible and authentic across mediums like streaming, gaming, and films.
We’ve seen Spotify and OpenAI tease their advancements in voice translation and speech capabilities, and we’re excited to share news of our own developments.
This is me speaking Spanish, thanks to amazing work by @Spotify AI engineers. The translation & voice-cloning are fully done by AI. Language can create barriers of understanding & thus fuel division. I can't wait for AI to break down this barrier & reveal our common humanity ❤… pic.twitter.com/pH8EYcBDj2
— Lex Fridman (@lexfridman) September 25, 2023
The upcoming tool is not just about translation; it’s about preserving the speaker's identity and original speech patterns across languages, allowing for a more connected and immersive experience than what traditional captioning can offer.
Imagine an educational video in English. If somebody only speaks Spanish (but would otherwise find the subject interesting), that’s a problem. We want to be able to generate the original person speaking the original message naturally in native-grade Spanish.
This requires combining voice conversion, voice cloning and multilingual speech synthesis capabilities inside a single new tool. Here, voice cloning lets us preserve the speaker’s identity - the sound of their voice. We use speech synthesis to generate new utterances in a different language as if it’s the same person speaking. Voice conversion comes into play because we want to preserve the original emotions, intent, and style of delivery for maximum immersion.
Automate video voiceovers, ad reads, podcasts, and more, in your own voice
We’ve put a lot of research and innovation into developing technology that can render human speech ultra-realistically, understand context and encode voice profiles. Our AI voice translation tool is a significant step towards enabling creators to widen their reach and helping prospective audiences discover content they find relevant and captivating, regardless of what language they understand.
Dubbing is a process for providing a video with a different language soundtrack by replacing the original actors' voices with those of performers speaking a different language - aka "re-voicing" - traditionally a costly and time-consuming task. At Eleven, our goal is to do this automatically while preserving the original voices across languages.
Voice conversion allows one person to speak in the voice of another. It uses voice cloning, to encode a target voice and overlay it onto source voice. The result is the original message seemingly spoken by somebody else.
Text-to-speech (TTS) is the root of all speech synthesis technology. TTS tech improved radically over the years though it still often sounds robotic. That's because pronouncing words fluently is on its own insufficient to give speech human quality. It's the intent-driven tone and pacing that come from understanding what is being said that make it sound natural. At Eleven, we try to achieve just that: by exposing our model to a wealth of human-speech data, we train it to understand both the logical and emotional context of utterances, and to adjust delivery accordingly.

Our AI text to speech technology delivers thousands of high-quality, human-like voices in 32 languages. Whether you’re looking for a free text to speech solution or a premium voice AI service for commercial projects, our tools can meet your needs
We're looking forward to the October release and to changing the way we engage with multilingual content.
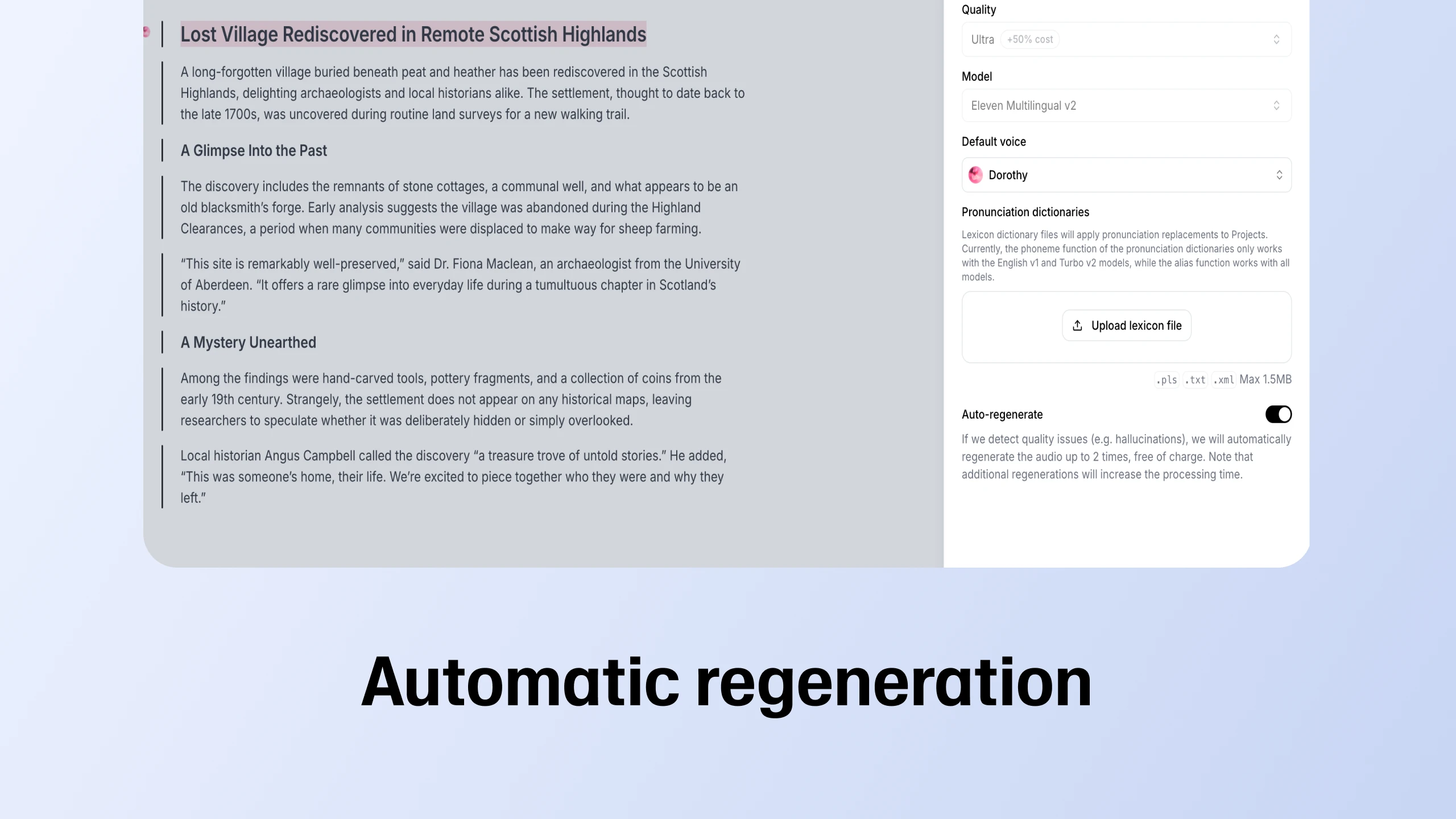
Our long form text editor now lets you regenerate faulty fragments, adjust playback speed, and provide quality feedback

Developers brought ideas to life using AI, from real time voice commands to custom storytelling